Memakai Google BigQuery Untuk Laporan Inventory FIFO
Menghitung data untuk laporan inventory berbasis FIFO sebenarnya tidak kompleks. Saya hanya perlu mengetahui jumlah item yang tersisa, lalu mencari transaksi pembelian dan retur terbaru hingga mencapai nilai jumlah item tersisa. Sama sekali tidak perlu menghitung penjualan dan transaksi lainnya dari awal. Sebagai contoh, karena pada awalnya saya menggunakan Firestore, saya bisa membuat sebuah function seperti berikut ini untuk mendapatkan pembelian dan retur hingga jumlah item tersisa:
const periodsSnapshot = await firestore.collection(`items/${itemId}/periods`) .where(FieldPath.documentId(), '<=', asOfDateLabel) .get();const sortedPeriodsSnapshotDocs = periodsSnapshot.docs.sort((a, b) => (a.id < b.id) ? 1 : -1);for (const periodDoc of sortedPeriodsSnapshotDocs) { const stocksSnapshot = await firestore.collection(`items/${itemId}/periods/${periodDoc.id}/stocks`) .where('date', '<=', asOfDate) .orderBy('date', 'desc') .get(); for (const stockDoc of stocksSnapshot.docs) { const stock = <Stock> stockDoc.data(); if ((stock.type === purchase) || (stock.type === salesReturn))) { if (qtyLeft >= stock.qty) { result.push(stock); qtyLeft -= stock.qty; } else { stock.qty = qtyLeft; stock.amount = stock.qty * stock.rate; result.push(stock); qtyLeft = 0; break; } } } if (qtyLeft <= 0) { break; }}Sebuah function yang sederhana, bukan? Akan tetapi, alangkah terkejutnya saya ketika harus menunggu hingga 8,5 menit agar laporan siap ditampilkan pada jumlah data yang cukup besar. Mengapa demikian?
Pada Firestore, saya menggunakan beberapa nested sub-collections mengingat saya tidak mungkin menyimpan seluruh perubahan stok di sebuah document Item tunggal. Hal ini karena sebuah dokumen di Firestore hanya boleh berukuran maksimum 1 MB. Selain itu, saya tidak ingin selalu mengambil informasi stok setiap kali mendapatkan document Item. Saat saya mengambil sebuah dokumen Item, nilai sub-collection tidak akan ikut dikembalikan. Akan tetapi, pada kasus ini, saya berharap bisa mendapatkan seluruh nested sub-collections yang dibutuhkan hanya dalam satu kali pemanggilan.
Sayangnya, hal ini tidak dapat dilakukan! Oleh sebab itu, kinerja function menjadi lambat karena waktu habis terpakai untuk berulang kali melakukan pemanggilan ke server Firestore. Bila terdapat 1.000 item, maka saya akan melakukan 1.001 pemanggilan: 1 pemanggilan untuk mendapatkan seluruh item dan 1.000 kali pemanggilan untuk mendapatkan informasi stok untuk masing-masing item. Ini mirip seperti masalah query N+1 di ORM. Walaupun Firestore adalah database yang scalable, ia tidak bisa mengatasi masalah kinerja yang ditimbulkan oleh ‘kebodohan’ aplikasi yang menggunakannya seperti pada kasus ini.
Beruntungnya, Google menyediakan produk BigQuery yang memang ditujukan untuk keperluan analisis seperti laporan. Google BigQuery adalah sebuah layanan database SQL serverless yang dirancang untuk men-query data dalam jumlah besar. Sesuai namanya, BigQuery lebih optimal untuk layanan baca ketimbang tulis. BigQuery tidak mendukung transaksi. Operasi DML seperti INSERT dan DELETE di BigQuery juga dibatasi oleh kuota. Sebagai contoh, query INSERT hanya diperbolehkan hinggal maksimal 1.000 operasi per hari sementara operasi lain seperti UPDATE dan DELETE hanya maksimum 200 operasi per hari. Sebagai gantinya, terdapat fasilitas streaming inserts yang menambahkan data secara asynchronous dan tidak dibatasi oleh kuota harian, hanya maksimum 100.000 baris per detik.
Selain itu, BigQuery juga tidak mendukung konsep seperti primary key untuk menghindari penambahan baris data yang sama. Streaming inserts mendukung insertId untuk menghindari memasukkan data yang sama lebih dari sekali, akan tetapi insertId hanya diingat setidaknya paling cepat 1 menit (tidak ada jaminan). Dengan demikian, BigQuery lebih tepat untuk data incremental dimana jumlah baris (record) terus bertambah baru tanpa harus menghapus atau mengubah baris lama.
Lalu apa alasan menggunakan BigQuery bila kinerjanya tulisnya parah? Apalagi bila bukan kinerja bacanya! Dengan SQL yang tepat, BigQuery bisa memberikan hasil dalam waktu yang cepat. Sebagai contoh, BigQuery bisa memproses query yang membaca data sebanyak 100 milliar record (sekitar 7TB) dalam waktu sekitar 30 detik. Berdasarkan pengakuan Google, BigQuery sudah dipakai di internal Google untuk berbagai keperluan analitik sejak tahun 2006. Selain itu, BigQuery juga memiliki harga yang murah berdasarkan jumlah byte yang di-query. 1 TB pertama gratis, selanjutnya 5 USD untuk setiap TB.
Saya segera membuat sebuah tabel baru di BigQuery dengan nama stocks dan menambahkan data ke dalamnya. Setelah itu, pertanyaan berikutnya adalah seperti apa query SQL yang harus saya berikan? Bagaimana caranya menghitung nilai inventory FIFO dalam 1 query SQL tunggal?
Saya akan mulai dengan query yang menghitung jumlah item yang tersedia pada tanggal yang ditentukan:
SELECT itemId, SUM(qty) AS finalQtyFROM inventory.stocksWHERE date <= TIMESTAMP('2018-12-31 23:59:00')GROUP BY itemId| row | itemId | finalQty |
|---|---|---|
| 1 | 6 | 18 |
| 2 | 7 | 133 |
| 3 | 8 | 102 |
Langkah berikutnya, untuk mempermudah mendapatkan transaksi pembelian atau retur terakhir, saya bisa menggunakan field reverseQty yang merupakan hasil kalkulasi seperti pada query berikut ini:
SELECT itemId, date, qty, SUM(qty) OVER ( PARTITION BY itemId ORDER BY date ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS reverseQty, ROW_NUMBER() OVER (PARTITION BY itemId ORDER BY date) AS rowNumFROM inventory.stocksWHERE type IN ('purchase', 'purchase return') AND date <= TIMESTAMP('2018-12-31 23:59:00')ORDER BY itemId, date;| row | itemId | date | qty | reverseQty | rowNum |
|---|---|---|---|---|---|
| 1 | 6 | 2018-11-09 | 10 | 40 | 1 |
| 2 | 6 | 2018-11-19 | 10 | 30 | 2 |
| 3 | 6 | 2018-12-03 | 10 | 20 | 3 |
| 4 | 6 | 2018-12-27 | 10 | 10 | 4 |
| 5 | 7 | 2018-09-05 | 10 | 170 | 1 |
| 6 | 7 | 2018-09-27 | 30 | 160 | 2 |
| 7 | 7 | 2018-10-12 | 30 | 130 | 3 |
| 8 | 7 | 2018-11-09 | 20 | 100 | 4 |
| 9 | 7 | 2018-11-19 | 20 | 80 | 5 |
| 10 | 7 | 2018-12-03 | 20 | 60 | 6 |
| 11 | 7 | 2018-12-27 | 10 | 40 | 7 |
| 12 | 7 | 2018-12-31 | 30 | 30 | 8 |
| 13 | 8 | 2018-09-27 | 20 | 140 | 1 |
| 14 | 8 | 2018-10-12 | 30 | 120 | 2 |
| 15 | 8 | 2018-10-15 | 10 | 90 | 3 |
| 16 | 8 | 2018-11-09 | 10 | 80 | 4 |
| 17 | 8 | 2018-11-19 | 10 | 70 | 5 |
| 18 | 8 | 2018-12-03 | 30 | 60 | 6 |
| 19 | 8 | 2018-12-31 | 30 | 30 | 7 |
Pada query di atas, saya menggunakan analytic window function untuk menghitung nilai di field reverseQty. Ini sangat berguna untuk menghindari JOIN. Pada query tersebut, untuk menghitung reverseQty, BigQuery akan melakukan hal berikut ini:
SUM(qty) OVER: analytic function yang dipakai, lihat langkah 4.PARTITION BY itemId: Setiap baris yang ada dikelompokkan berdasarkanitemId.ORDER BY date: Untuk setiap partisiitemId, baris diurutkan berdasarkandate.ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING: Hitung nilaiSUM(qty)untukqtymulai dari baris saat ini hinggaqtyterakhir di partisiitemIdyang sama.
Sebagai hasil akhirnya, nilai reverseQty adalah nilai kumulatif dari qty mulai dari tanggal paling terakhir hingga tanggal paling awal.
Saya juga melakukan hal yang sama pada field rowNum. Nilai ini dipakai sebagai pengenal baris yang unik. Saya tidak bisa menggunakan date karena bisa saja terdapat dua atau lebih baris dengan nilai date yang sama. Oleh sebab itu, saya menggunakan window function ROW_NUMBER() untuk mendapatkan nilai yang unik untuk masing-masing baris.
Langkah selanjutnya, saya perlu mencari nilai tanggal dimana saya harus mulai mengembalikan nilai inventory. Sebagai contoh, untuk item 6, karena finalQty bernilai 18, maka nilai inventory yang tersisa adalah pembelian pada tanggal 2018-12-23 dan 2018-12-27. Perlu diperhatikan bahwa untuk stok pada pembelian 2018-12-23, sudah ada 2 item yang terjual sehingga hanya 8 item yang tersisa, seperti yang terlihat pada:
2018-12-03 82018-12-27 10---------------------- + 18Untuk mengembalikan nilai rowNum yang tepat, dengan asumsi bahwa query yang mengembalikan totalQty adalah queryA dan query yang mengembalikan reverseQty adalah queryB, maka saya bisa menggunakan query seperti berikut ini:
SELECT DISTINCT T.itemId, finalQty, LAST_VALUE(rowNum) OVER ( PARTITION BY R.itemId ORDER BY date, rowNum ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS startRowNumFROM itemTotal T JOIN itemReverseTotal R ON T.itemId = R.itemId AND R.reverseQty >= T.finalQty| row | itemId | finalQty | startRowNum |
|---|---|---|---|
| 1 | 6 | 18 | 3 |
| 2 | 7 | 133 | 5 |
| 3 | 8 | 102 | 2 |
Berikut ini adalah langkah-langkah yang ditempuh untuk menghitung nilai field startRowNum:
LAST_VALUE(rowNum): analytic function yang dipakai, lihat langkah 4.PARTITION BY R.itemId: Setiap baris yang ada dikelompokkan berdasarkanitemId.ORDER BY date, rowNum: Untuk setiap partisiitemId, baris diurutkan berdasarkandatedanrowNum.ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING: Kembalikan nilairowNumuntuk baris terakhir (di partisiitemIdyang sama).
Karena pada akhir query, saya menambahkan R.reverseQty >= T.finalQty, maka startRowNum akan mengembalikan nilai rowNum untuk sebuah itemId dimana nilai total pembelian sudah sama dengan atau melebihi nilai finalQty.
Sampai disini, saya sudah memiliki tiga query terpisah yang mewakili urutan langkah-langkah yang harus ditempuh! Bagaimana menyatukannya menjadi sebuah query tunggal? Saya bisa menggunakan fitur Common Table Expression (CTE) di SQL. CTE mirip seperti subquery tetapi lebih mudah dibaca dan dipahami terutama untuk kasus yang saya hadapi saat ini. Seperti pada database SQL lainnya (Oracle atau SQL Server), saya bisa menerapkan fitur CTE dengan menggunakan klausa WITH, seperti yang terlihat pada SQL berikut ini:
WITH itemTotal AS ( SELECT itemId, SUM(qty) AS finalQty FROM inventory.stocks WHERE date <= TIMESTAMP('2018-12-31 23:59:00') GROUP BY itemId ), itemReverseTotal AS ( SELECT itemId, date, qty, SUM(qty) OVER ( PARTITION BY itemId ORDER BY date ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS reverseQty, ROW_NUMBER() OVER (PARTITION BY itemId ORDER BY date) AS rowNum FROM inventory.stocks WHERE type IN ('purchase', 'purchase return') AND date <= TIMESTAMP('2018-12-31 23:59:00') ), itemStartRowNum AS ( SELECT DISTINCT T.itemId, finalQty, LAST_VALUE(rowNum) OVER ( PARTITION BY R.itemId ORDER BY date, rowNum ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS startRowNum FROM itemTotal T JOIN itemReverseTotal R ON T.itemId = R.itemId AND R.reverseQty >= T.finalQty )SELECT R.itemId, R.date, CASE WHEN R.rowNum = S.startRowNum THEN S.finalQty - (R.reverseQty - R.qty) ELSE R.qty END AS qty, S.finalQtyFROM itemReverseTotal R JOIN itemStartRowNum S ON R.itemId = S.itemIdWHERE R.rowNum >= S.startRowNum AND S.finalQty > 0ORDER BY R.itemId, R.dateCukup satu query SQL untuk mendapatkan hasil laporan inventory berbasis FIFO! Ini pasti akan memiliki kinerja yang lebih baik dibandingkan dengan harus menggunakan stored procedure apalagi memanggil query sampai tiga kali. Saya segera mencoba mengerjakan query ini di dashboard BigQuery seperti yang terlihat pada gambar berikut ini:
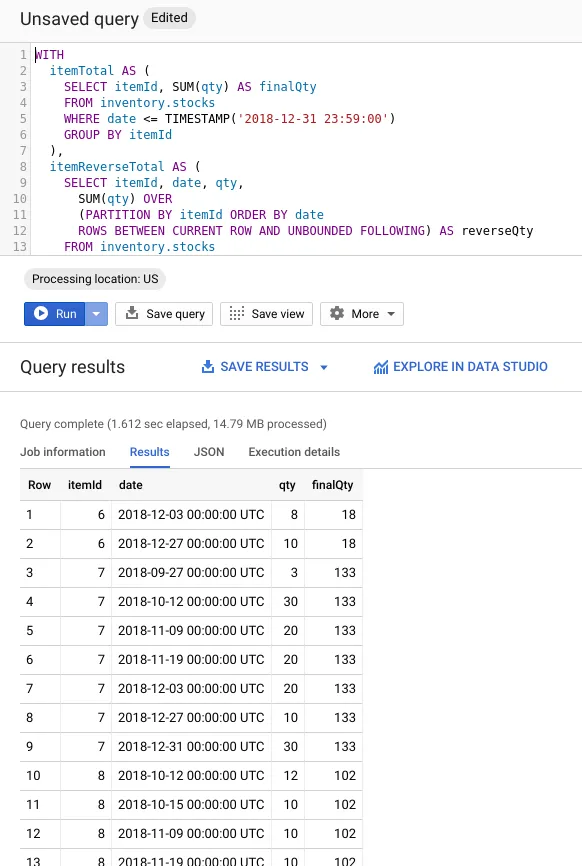
Hasil yang cukup positif karena query hanya memakan waktu 1,6 detik untuk memproses 645.973 baris (dengan ukuran 14,79 MB).
Sekarang saatnya membuat Firebase Function yang mengerjakan query dan mengembalikan hasilnya dalam bentuk JSON. Untuk itu, saya perlu menambahkan dependency ke @google-cloud/bigquery di npm. Setelah itu, saya menulis kode program seperti berikut ini:
import {BigQuery} from '@google-cloud/bigquery';
export const getInventoryValuationReportData = functions.https.onRequest((req, res) => { return cors(req, res, () => { const bigquery = new BigQuery(); bigquery.query(`...ganti dengan query SQL...`).then(([rows]) => { res.send(rows); }).catch(err => { res.status(500).send({ error: `Encountered error: ${err}` }); }); });});Sekarang, saya hanya perlu mengatur data source untuk mendapatkan JSON dari URL untuk Firebase Function di atas. Berkat BigQuery, saya akhirnya bisa menampilkan laporan secara cepat tanpa harus melakukan instalasi aplikasi server database seperti Oracle atau SQL Server.