Memakai FSCrawler Untuk Mencari Teks Di Gambar
John adalah seorang hacker yang belakangan ini sangat tertarik pada Jessica. Selama beberapa bulan terakhir, dia membuat scraper, backdoor, dan memanfaatkan berbagai exploit lainnya untuk mendapatkan informasi mengenai Jessica. “Apa hobinya? Apa makanan yang dia suka? Apa warna favoritnya?” pikir John tanpa sadar bahwa obsesinya sudah melanggar privasi Jessica. Dia segera men-klik sebuah folder yang berisi seluruh informasi mengenai Jessica yang sudah dikumpulkannya selama setahun. Awalnya John penuh dengan rasa penasaran dan bahagia menelusuri setiap file gambar, video, PDF, dan dokumen lainnya satu per satu. Namun setelah 15 menit berlalu, John mengeluh, “Banyak sekali file-nya, tidak mungkin aku membuka satu per satu. Aku hanya ingin lihat yang penting saja.”
“Bila hanya file teks, aku bisa membuat script sederhana untuk melakukan pencarian,” pikir John, “Tapi kebanyakan adalah file gambar yang berisi screenshot percakapan di media sosial. Teks di gambar tidak akan bisa dibaca begitu saja.” John tidak habis pikir kenapa banyak orang yang mengarsip percakapan dalam bentuk screenshot. “Selain susah untuk dicari dikemudian hari, juga boros penyimpanan. Menyimpan sebuah kalimat dengan 150 huruf hanya membutuhkan 150 bytes sementara sebuah file gambar JPG rata-rata berukuran 11.800 bytes hanya untuk potongan kalimat singkat.”
Walaupun demikian, sebagai seorang hacker, John tidak pernah kehabisan ide. “Apakah aku harus membuat sebuah aplikasi web yang memakai Google Cloud Vision API?” John mulai mencari solusi, “Tidak! Masih belum gajian, bahaya kalo tagihan membengkak!” Tiba-tiba kepalanya terasa pusing. Bila gaji belum turun, bagaimana dia bisa membawa Jessica ke dinner romantis di restoran mewah? “Ah, kenapa susah sekali hidup di Indonesia? Sementara di negara seperti US, lagi pada sibuk cari programmer akibat the great resignation,” pikir John, “Semoga Jessica mau diajak makan nasi goreng atau pecel ayam, toh yang penting bukan makanannya tapi kebersamaannya.” Memikirkan makanan, perut John yang kosong langsung bunyi keroncongan. Namun, John pantang menyerah. Ia memutuskan untuk memakai solusi offline, selain murah juga lebih aman karena Jessica tidak akan tahu data-nya sedang dianalisa.
John menemukan beberapa library optical character recognition (OCR) yang populer seperti Tesseract OCR. “Wah, nama yang familiar,” John mencoba berpikir, “Oh iya, ini ‘kan batu yang dipakai oleh Loki yang didalamnya berisi space stone.” Dalam kepalanya langsung muncul adegan saat Loki menyerang New York dan Avenger bersatu melawannya. Butuh waktu sejenak bagi John sebelum akhirnya dia kembali ke dunia nyata. John langsung sreg dengan Tesseract OCR. Namun, selum mengerjakan sesuatu, John selalu berusaha membandingkan beberapa solusi lain terlebih dahulu. Upayanya tidak sia-sia, karena pada akhirnya John menemukan FSCrawler. FSCrawler pada dasarnya adalah sebuah aplikasi yang melakukan crawling pada folder yang ditentukan. Untuk membaca isi dokumen, FSCrawler menggunakan Apache Tika.
“Si Tika tetangga sebelah cantik juga,” pikir John. Tika dapat membaca file populer seperti PDF, Microsoft Excel, JPEG, PNG, GIF, BMP, MP4, SQLite dan sebagainya. “Wah, mantap bener si Tika,” John kagum. Apalagi setelah tahu bahwa bila JAR Tesseract OCR terdeteksi, Tika akan memiliki dukungan OCR. Setelah membaca isi file beserta metadata-nya, FSCrawler akan menyimpan hasil baca tersebut ke Elasticsearch. “Wah, ini bisa dihubungkan ke Kibana untuk pencarian sehingga saya tidak perlu membuat front end lagi.” John sudah terbiasa memakai Kibana saat training untuk menjadi tim biru di dunia per-hacker-an. Bila tim merah yang menyerang menggunakan aplikasi seperti Metasploit, maka tim biru yang bertahan lebih sering menggunakan Kibana untuk membaca laporan dan mencari aktifitas yang mencurigakan.
John tidak ingin repot melakukan instalasi, sehingga dia memutuskan untuk menggunakan Docker Compose. Lagipula di https://fscrawler.readthedocs.io/en/fscrawler-2.8/installation.html#using-docker-compose sudah ada contoh yang bisa dipakai. John segera membuat sebuah folder search dengan isi seperti berikut ini:
Directorysearch
- docker-compose.yaml
Directoryconfig
- …
Directoryjessica
- …
John kemudian mengisi docker-compose.yaml dengan nilai seperti berikut ini:
version: "3"services: fscrawler: image: dadoonet/fscrawler:2.8 volumes: - ${PWD}/config:/root/.fscrawler - ${PWD}/jessica:/tmp/es:ro depends_on: - elasticsearch - kibana ulimits: memlock: soft: -1 hard: -1 elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.16.2 environment: - bootstrap.memory_lock=true - discovery.type=single-node - ingest.geoip.downloader.enabled=false - cluster.routing.allocation.disk.threshold_enabled=false - ES_JAVA_OPTS=-Xms4g -Xmx4g ports: - 9200:9200 ulimits: memlock: soft: -1 hard: -1 kibana: image: docker.elastic.co/kibana/kibana:7.16.2 depends_on: - elasticsearch ports: - 5601:5601 ulimits: memlock: soft: -1 hard: -1Disini John membuat 3 service dengan nama fscrawler, elasticsearch dan kibana. Docker Compose secara otomatis akan membuat jaringan bridge dimana mereka bisa saling menghubungi melalui nama service tersebut, misalnya service fscrawler dan kibana bisa membaca dan menulis ke Elasticsearch melalui http://elasticsearch:4200.
Pada service fscrawler, John memetakan folder config ke /root/.fscrawler di dalam container. FSCrawler akan membaca file konfigurasi dari folder ini. John juga memetakan folder jessica ke /tmp/es di dalam container. Ini adalah nilai default untuk folder dimana FSCrawler akan mencari dokumen yang akan diproses. Image Docker yang dipakai oleh John, dadoonet/fscrawler:2.8, sudah mendukung Elasticsearch 7 dan juga sudah dilengkapi dengan Tesseract OCR sehingga dapat mengkonversi isi file gambar menjadi teks.
Sementara itu, untuk service elasticsearch, John menambahkan pengaturan ingest.geoip.downloader.enabled=false supaya Elasticsearch bisa tetap jalan walaupun komputer tidak terhubung ke Internet. Ia juga menambahkan cluster.routing.allocation.disk.threshold_enabled=false supaya Elasticsearch tetap akan bisa bekerja walaupun free space sudah di bawah 15%. Sebenarnya John memiliki harddisk dengan ukuran 1 TB. “Ini tidak adil: 15% dari 1 TB adalah 150 GB. Ini adalah jumlah ruang bebas yang besar, tapi Elasticsearch secara default hanya melihat persentase,” keluh John, “Saya tidak akan pernah menghapus file hanya karena masalah 15% ini.” John tidak sadar bahwa dirinya sudah menjadi data hoarder.
Sebelum bisa menjalankan proses crawling, John perlu membuat definisi job untuk FSCrawler terlebih dahulu. “Apakah saya perlu copy paste dari web?” pikir John, “Tidak. Pasti ada cara yang lebih gampang.” Sikap malas John membuatnya menemukan perintah untuk menghasilkan konfigurasi global secara cepat:
docker compose run fscrawler fscrawlerSetelah perintah di atas dijalankan, ia menemukan file baru di folder config:
Directorysearch
- docker-compose.yaml
Directoryconfig
Directory6
- _settings_folder.json
- _settings.json
Directory7
- _settings_folder.json
- _settings.json
- _wpsearch_settings.json
Directoryjessica
- …
Folder 6 untuk Elasticsearch 6 dan folder 7 untuk Elasticsearch 7. Karena John memakai Elasticsearch 7, ia hanya perlu mengubah file yang ada di folder 7. Di sini, John bisa mengubah mapping untuk index Elasticsearch yang dipakai. Salah satu field yang mapping-nya perlu diubah adalah content. “Bila aku tidak memakai fielddata, maka nilai ‘aku cinta kamu’ adalah sebuah nilai tunggal, tapi aku ingin agar kalimat itu dilihat sebagai 3 nilai berbeda, ‘aku’, ‘cinta’ dan ‘kamu’,” pikir John. Lagi-lagi ia mengeluh, “Elasticsearch bisa melakukan full-text searching, tetapi mengapa untuk agregasi dan scripting harus mengubah mapping? Mengapa tidak langsung saja biar saya tidak perlu repot mengubah mapping lagi?” Ia tidak tahu bahwa keputusan ini sengaja diberikan untuk menghemat memori, apalagi tidak semua orang butuh agregasi untuk teks yang panjang. John kemudian mengubah file config/_default/7/_settings.json di bagian berikut ini:
..."content": { "type": "text", "fielddata": true, "analyzer": "indonesian"},...Setelah ini, John kemudian membuat file baru di config/jessica/_settings.yaml dengan isi seperti berikut ini:
name: jessicafs: url: /tmp/es continue_on_error: "true" ignore_above: 100mbelasticsearch: nodes: - url: http://elasticsearch:9200Ini adalah definisi job untuk FSCrawler dengan nama jessica. Definisi ini akan membaca file yang ada di folder /tmp/es (di dalam container Docker) yang berukuran maksimal 100 MB. Sekarang, John sudah siap untuk menjalankan proses crawling. Ia bisa memakai docker compose up untuk menjalankan seluruh container secara bersamaan. Namun, ia memilih menjalankan setiap service masing-masing di terminal tersendiri sehingga bisa melihat hasil log-nya dengan mudah:
docker compose up elasticsearchdocker compose up kibanaJohn kemudian menjalankan FSCrawler dengan memberikan perintah berikut ini:
docker compose run fscrawler fscrawler jessicaSampai disini, John bisa membuka Kibana melalui http://localhost:5601 di browser-nya. Seperti biasa, untuk memakai sebuah index yang belum pernah didefinisikan sebelumnya di Kibana, John perlu membuat Index Pattern baru dengan memilih menu Stack Management (di bagian Management), Index Patterns (di bagian Kibana) dan men-klik tombol Create index pattern. John menggunakan nama jessica (tanpa tanda bintang) sebagai nama index pattern dan memilih ”--- I don’t want to use the time filter ---” dari timestamp sebelum men-klik tombol Create index pattern. Untuk memastikan FSCrawler bekerja, John kemudian membuka Discover (di Analytics). Disini John dapat melihat isi setiap file yang ada. Karena hanya tertarik pada isi file, John memilih “content” dari panel di sebelah kiri. Sekarang, hanya isi file yang ditampilkan di tabel seperti yang terlihat pada gambar berikut ini:
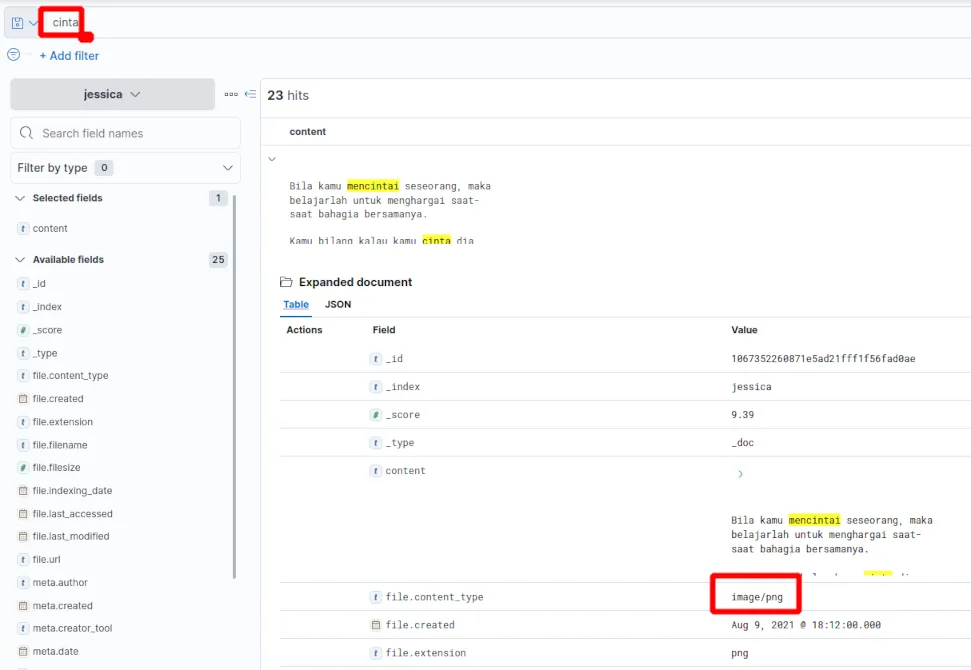
“Semua gambar dan dokumen seperti PDF sudah menjadi tulisan yang bisa dicari,” John langsung kagum, “Ini sangat membantu sekali. Walaupun Tesseract OCR tidak mengenali semua tulisan dengan sempurna, ini jauh lebih baik bila saya harus membuka setiap dokumen satu per satu.”
Setelah memastikan dokumen sudah ditambahkan oleh FSCrawler, John langsung kembali ke tujuan utamanya: mencari kata populer. Untuk itu, dia memilih Visualize Library (di bagian Analytics), Create new visualizations, Aggregation based, Tag cloud, dan jessica sebagai sumber data. Setelah itu, John men-klik tombol Add di bagian Buckets dan memilih Tags. Di bagian Aggregations, John memilih Terms. Setelah itu, John mengisi Field dengan content, dan Size dengan nilai yang besar seperti 20. Sebagai langkah terakhir, John men-klik tombol Update. Kibana akan menampilkan daftar kata populer seperti yang terlihat pada gambar berikut ini:
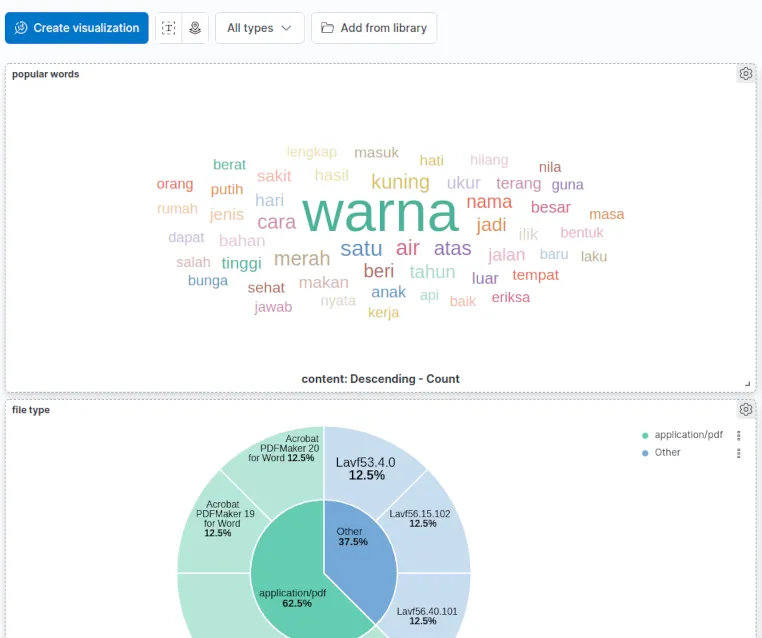
Melihat hasil tag cloud di atas, John menyimpulkan, “Mmm… sepertinya Jessica sangat tertarik dengan warna terutama warna kuning dan merah”. Ia tidak sadar bahwa kesimpulannya belum tentu benar. Salah satu tantangan utama di machine learning dan statistik adalah mengumpulkan data yang benar dan akurat. Bagaimana bila file yang John kumpulkan sebagian besar adalah email marketing yang diterima oleh Jessica? Walaupun ada kolerasi dengan preferensi Jessica, seharusnya John bisa memberikan bobot lebih untuk informasi yang datang langsung dari media sosial Jessica.
Bila Terms lebih tepat untuk informasi Top-N, maka Significant Terms mengembalikan informasi yang lebih berguna bila dipakai bersama dengan filter. Sebagai contoh, saat John menambahkan filter “suka”, ini perbedaan antara Terms dan Significant Terms:
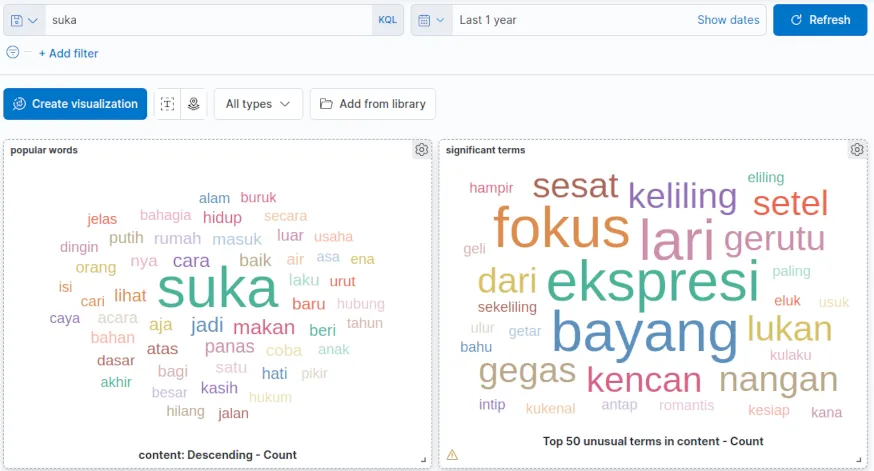
Significant Terms memperlihatkan kata yang lebih unik yang dipakai bersama dengan “suka”. John langsung bahagia melihat bahwa kata “suka” dipadukan bersama dengan kata “kencan”. Namun ada beberapa kata yang John tidak suka seperti “gegas” dan “gerutu”.
John belum sempat selesai mengambil kesimpulan ketika tiba-tiba layar komputernya muncul tulisan hijau aneh. “Screensaver the Matrix?” John terserentak hampir jatuh dari kursinya, “Apa komputerku kena virus? Belakangan ini banyak celah keamanan Log4j dan Elasticsearch/Kibana termasuk yang memakai Log4j. Tapi bagaimana mungkin?”
John dalam keadaan panik langsung mematikan komputernya dengan mencabut dari sumber listrik. Anehnya, di monitor masih muncul tulisan dengan font klasik yang berisi: “jangan lupa follow saya”. John mulai panik, “Apa aku terlalu banyak di depan komputer?” Jantungnya berdebar kencang melihat situasi yang tidak wajar ini.
Suara keras membuat John kaget: “Hey, John.” Ternyata Tommy sudah ada di belakang John. “Malam ini malam tahun baru, ayo ikut kita pesta,” Tommy menawarkan dua pil kepada John, “Mau pil biru atau pil merah?” Ini persis seperti apa yang ditawarkan Morpheus kepada Neo. John menjadi semakin bingung. Apakah Matrix benar-benar ada? Ia tidak sadar bahwa sesungguhnya selama ini ia tidak lebih dari imajinasi seorang arsitek. Entah apa yang akan terjadi di tahun 2022 baginya…